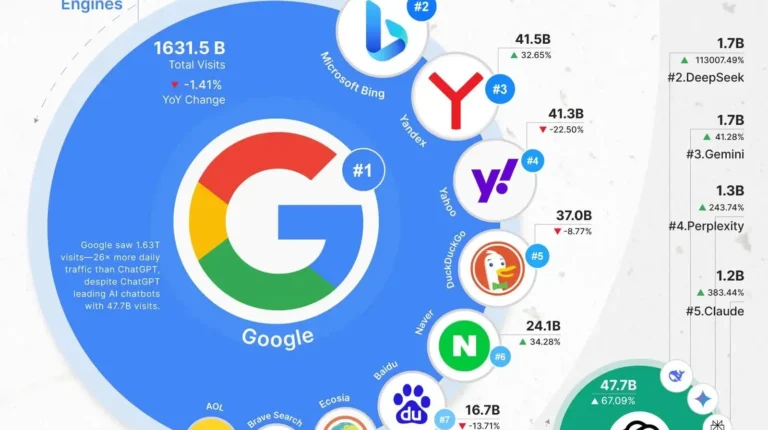
How to Get Your Business Found by ChatGPT, AI Assistants & Search Bots

You’ve optimized for Google. Maybe even Bing. But what about AI-powered assistants like ChatGPT or Microsoft Copilot? These tools now answer millions of local search queries—without users ever clicking through to a website.



